起源:DeepTech深科技前未几,硅谷的一家始创公司 Inception Labs 正式从隐身形式中浮出水面,推出了 Mercury,这是寰球首个基于分散模子(Diffusion Model)的贸易级言语模子。与传统的自回归年夜言语模子差别,Mercury 采取了一种全新的方式来天生文本跟代码,这使其在速率、效力跟潜伏利用方面都存在很多特别的上风。 (起源:Inception Labs)
(起源:Inception Labs) 从一对一到并行处置传统的年夜言语模子如都采取自回归方法任务。这种架构使得它们必需从左到右、一个标志(token)一个标志地猜测跟天生文本。这种次序处置方法成为这类模子速率的重要瓶颈。而 Mercury 却采取了分散模子架构。咱们都晓得这种架构之前重要利用于图像、视频跟音频天生模子,如 Midjourney、DALL-E 跟 Sora 等。但 Inception Labs 却胜利将这一技巧引入文本天生范畴:“咱们从一个大略的谜底估量开端,而后经由过程神经收集一直精粹,直到失掉终极谜底。”Ermon 说明道,“要害上风在于神经收集可能并行修正多个标志、多个词语。”详细来说,Mercury 以一种特别的方法处置文本数据。固然 Inception Labs 还未流露模子的参数数目、输入输出巨细、练习数据跟练习方式等具体信息,但咱们能够从 2023 年 10 月由 Inception Labs 结合开创人独特宣布的一篇研讨论文中懂得一些细节。该研讨采取“分数熵”(score entropy)练习文本分散模子,使模子学会估量两个标志之间的转换比率――即标志 y 准确的概率绝对于以后标志 x 准确的概率。在他们的试验中,研讨者经由过程在多个步调中随机逐步掩饰越来越多的标志,来向标志增加“噪声”。在推理阶段,模子从掩饰的标志开端,而后经由过程多个步调逐步撤消掩饰。估量的转换比率决议了在每个步调中怎样转变每个标志。这与图像分散模子相似,后者经由过程逐渐去除噪声来改良输出。这种计划让它天生速率比传统的言语模子快了十分多,运转在英伟达 H100 图形处置单位上时,Mercury Coder Small 可能以每秒 737 个标志的速率天生文本,而 Mercury Coder Mini 乃至到达了每秒 1,109 个标志。比拟之下,欧洲杯竞猜app同范例的模子如 Qwen 2.5 Coder 7B 每秒能天生 207 个标志,GPT-4o Mini 则为每秒 59 个标志。相称于 Mercury 的 Small 跟 Mini 版本比相似范围的编码模子快 3.5 至 18 倍。
从一对一到并行处置传统的年夜言语模子如都采取自回归方法任务。这种架构使得它们必需从左到右、一个标志(token)一个标志地猜测跟天生文本。这种次序处置方法成为这类模子速率的重要瓶颈。而 Mercury 却采取了分散模子架构。咱们都晓得这种架构之前重要利用于图像、视频跟音频天生模子,如 Midjourney、DALL-E 跟 Sora 等。但 Inception Labs 却胜利将这一技巧引入文本天生范畴:“咱们从一个大略的谜底估量开端,而后经由过程神经收集一直精粹,直到失掉终极谜底。”Ermon 说明道,“要害上风在于神经收集可能并行修正多个标志、多个词语。”详细来说,Mercury 以一种特别的方法处置文本数据。固然 Inception Labs 还未流露模子的参数数目、输入输出巨细、练习数据跟练习方式等具体信息,但咱们能够从 2023 年 10 月由 Inception Labs 结合开创人独特宣布的一篇研讨论文中懂得一些细节。该研讨采取“分数熵”(score entropy)练习文本分散模子,使模子学会估量两个标志之间的转换比率――即标志 y 准确的概率绝对于以后标志 x 准确的概率。在他们的试验中,研讨者经由过程在多个步调中随机逐步掩饰越来越多的标志,来向标志增加“噪声”。在推理阶段,模子从掩饰的标志开端,而后经由过程多个步调逐步撤消掩饰。估量的转换比率决议了在每个步调中怎样转变每个标志。这与图像分散模子相似,后者经由过程逐渐去除噪声来改良输出。这种计划让它天生速率比传统的言语模子快了十分多,运转在英伟达 H100 图形处置单位上时,Mercury Coder Small 可能以每秒 737 个标志的速率天生文本,而 Mercury Coder Mini 乃至到达了每秒 1,109 个标志。比拟之下,欧洲杯竞猜app同范例的模子如 Qwen 2.5 Coder 7B 每秒能天生 207 个标志,GPT-4o Mini 则为每秒 59 个标志。相称于 Mercury 的 Small 跟 Mini 版本比相似范围的编码模子快 3.5 至 18 倍。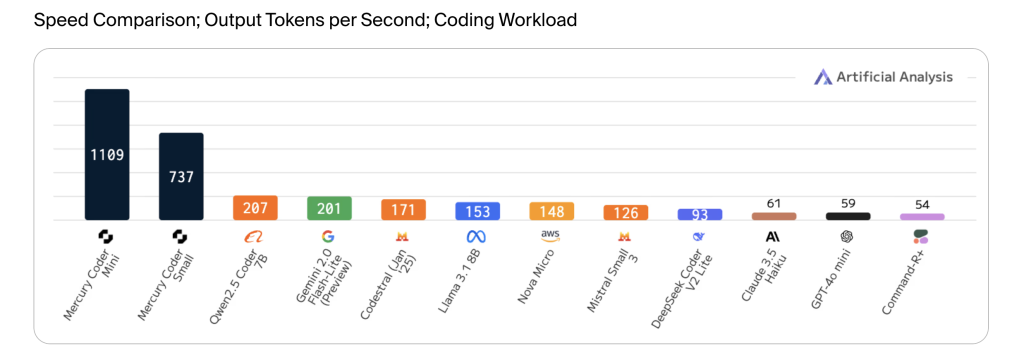 图丨输出速率对照(起源:Inception Labs)而在机能表示上,在六项编码基准测试中,Mercury Coder Small 在至少四项中超越了 Gemini 2.0 Flash-Lite、Claude 3.5 Haiku、GPT-4o Mini 跟 Qwen 2.5 Coder 7B 等竞争敌手。同时,体积更小的 Mercury Coder Mini 也在至少两项基准测试中击败了这些模子。不外,在全部六项基准测试中,DeepSeek Coder V2 Lite 都优于两个版本的 Mercury Coder。
图丨输出速率对照(起源:Inception Labs)而在机能表示上,在六项编码基准测试中,Mercury Coder Small 在至少四项中超越了 Gemini 2.0 Flash-Lite、Claude 3.5 Haiku、GPT-4o Mini 跟 Qwen 2.5 Coder 7B 等竞争敌手。同时,体积更小的 Mercury Coder Mini 也在至少两项基准测试中击败了这些模子。不外,在全部六项基准测试中,DeepSeek Coder V2 Lite 都优于两个版本的 Mercury Coder。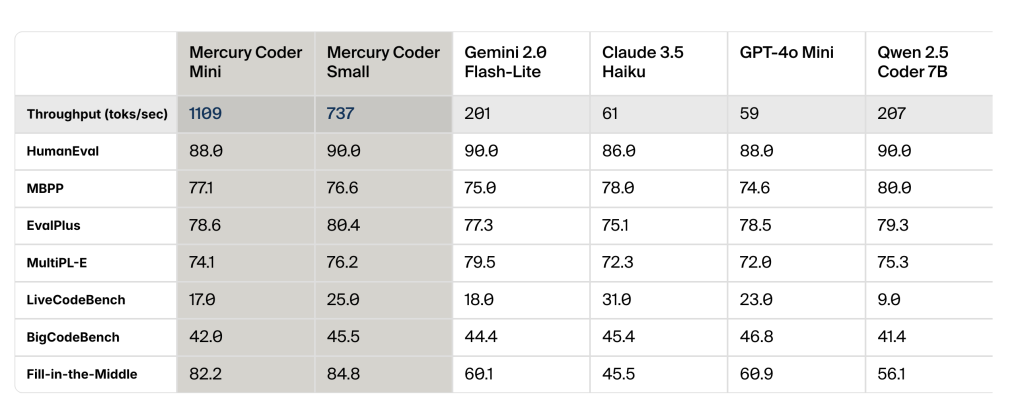 图丨基准测试成果(起源:Inception Labs)笔者用一道经典的小球碰撞标题停止了实测,并与其余模子停止了比拟。Prompt 如下:写一段 html 代码,网页旁边是一个正六边形,有一个存在初速率的质点在六边形中,遇到六边形的界限就反弹,每次遇到界限都时界限都随机变更色彩。先让尖子生 o3-mini-high 来打个样。
图丨基准测试成果(起源:Inception Labs)笔者用一道经典的小球碰撞标题停止了实测,并与其余模子停止了比拟。Prompt 如下:写一段 html 代码,网页旁边是一个正六边形,有一个存在初速率的质点在六边形中,遇到六边形的界限就反弹,每次遇到界限都时界限都随机变更色彩。先让尖子生 o3-mini-high 来打个样。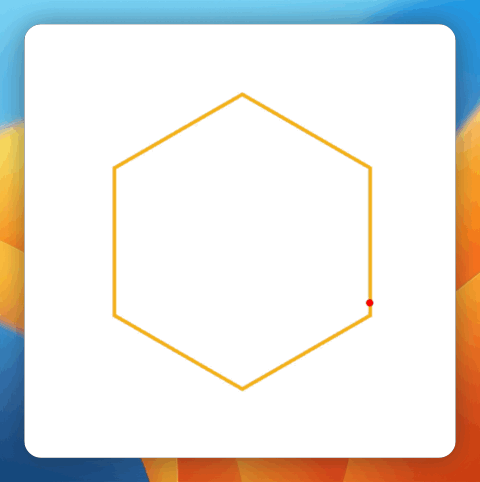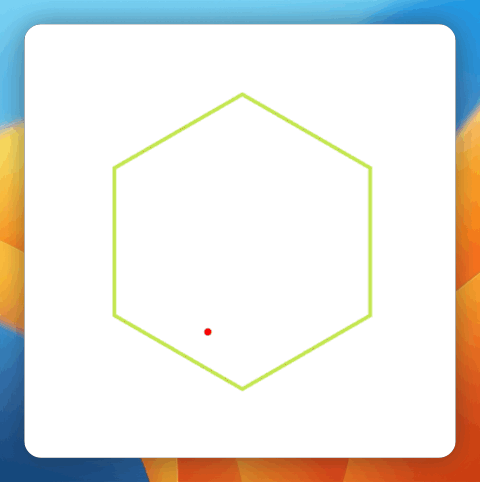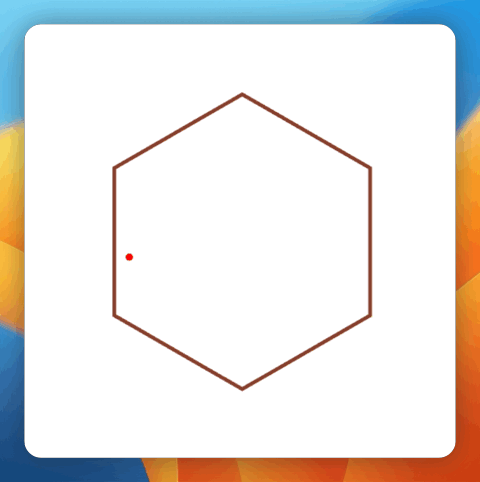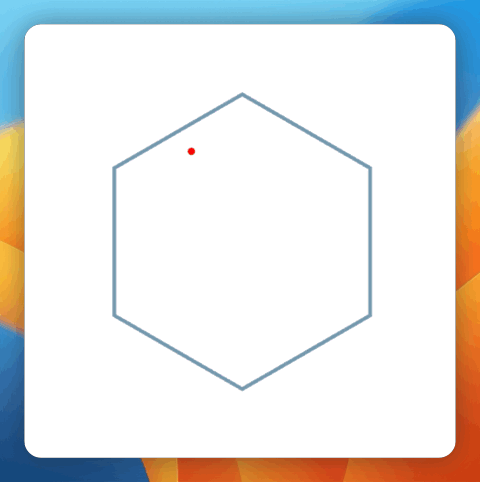 (起源:OpenAI o3-mini-high 天生)比拟之下,Mercury Coder 的表示能够说,要速率有速率,要品质有速率。碰撞检测十分简略粗鲁,六边形实现也有误。
(起源:OpenAI o3-mini-high 天生)比拟之下,Mercury Coder 的表示能够说,要速率有速率,要品质有速率。碰撞检测十分简略粗鲁,六边形实现也有误。
(起源:Inception Labs)从一对一到并行处置传统的年夜言语模子如都采取自回归方法任务。这种架构使得它们必需从左到右、一个标志(token)一个标志地猜测跟天生文本。这种次序处置方法成为这类模子速率的重要瓶颈。而 Mercury 却采取了分散模子架构。咱们都晓得这种架构之前重要利用于图像、视频跟音频天生模子,如 Midjourney、DALL-E 跟 Sora 等。但 Inception Labs 却胜利将这一技巧引入文本天生范畴:“咱们从一个大略的谜底估量开端,而后经由过程神经收集一直精粹,直到失掉终极谜底。”Ermon 说明道,“要害上风在于神经收集可能并行修正多个标志、多个词语。”详细来说,Mercury 以一种特别的方法处置文本数据。固然 Inception Labs 还未流露模子的参数数目、输入输出巨细、练习数据跟练习方式等具体信息,但咱们能够从 2023 年 10 月由 Inception Labs 结合开创人独特宣布的一篇研讨论文中懂得一些细节。该研讨采取“分数熵”(score entropy)练习文本分散模子,使模子学会估量两个标志之间的转换比率――即标志 y 准确的概率绝对于以后标志 x 准确的概率。在他们的试验中,研讨者经由过程在多个步调中随机逐步掩饰越来越多的标志,来向标志增加“噪声”。在推理阶段,模子从掩饰的标志开端,而后经由过程多个步调逐步撤消掩饰。估量的转换比率决议了在每个步调中怎样转变每个标志。这与图像分散模子相似,后者经由过程逐渐去除噪声来改良输出。这种计划让它天生速率比传统的言语模子快了十分多,运转在英伟达 H100 图形处置单位上时,Mercury Coder Small 可能以每秒 737 个标志的速率天生文本,而 Mercury Coder Mini 乃至到达了每秒 1,109 个标志。比拟之下,欧洲杯竞猜app同范例的模子如 Qwen 2.5 Coder 7B 每秒能天生 207 个标志,GPT-4o Mini 则为每秒 59 个标志。相称于 Mercury 的 Small 跟 Mini 版本比相似范围的编码模子快 3.5 至 18 倍。图丨输出速率对照(起源:Inception Labs)而在机能表示上,在六项编码基准测试中,Mercury Coder Small 在至少四项中超越了 Gemini 2.0 Flash-Lite、Claude 3.5 Haiku、GPT-4o Mini 跟 Qwen 2.5 Coder 7B 等竞争敌手。同时,体积更小的 Mercury Coder Mini 也在至少两项基准测试中击败了这些模子。不外,在全部六项基准测试中,DeepSeek Coder V2 Lite 都优于两个版本的 Mercury Coder。图丨基准测试成果(起源:Inception Labs)笔者用一道经典的小球碰撞标题停止了实测,并与其余模子停止了比拟。Prompt 如下:写一段 html 代码,网页旁边是一个正六边形,有一个存在初速率的质点在六边形中,遇到六边形的界限就反弹,每次遇到界限都时界限都随机变更色彩。先让尖子生 o3-mini-high 来打个样。(起源:OpenAI o3-mini-high 天生)比拟之下,Mercury Coder 的表示能够说,要速率有速率,要品质有速率。碰撞检测十分简略粗鲁,六边形实现也有误。







 推荐文章
推荐文章








){kind=link}
){kind=link}
){kind=link}
){kind=link}